This is part 2 of our blog series “Fantasy Service: The great cache game”. In the first part, we discussed about what problems we faced in scaling our APIs- why we introduced different layers of caching in our system and how we scaled our database, Redis, etc. We listed down 5 problems we faced and their solutions in part 1.
In this part, we will start with problem 6 and discuss what issues we faced after introducing the in-memory caching layer on our API servers. (I recommend you to read part 1 first). Let’s go🚀
Problem 6
The main issues left behind were data inconsistency, delay in reaching squad information to users and managing this system at higher throughput. You can read these problems in detail in our last blog.
Solution 6
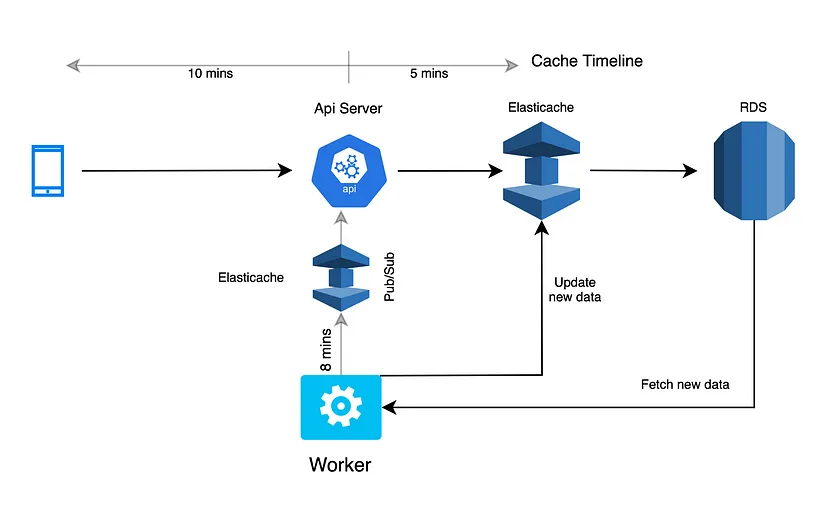
After part 1, we were using 3 layers for serving data of some APIs(match, matches, contest list). First the request will go from client -> to local cache -> to Redis -> then database.
To solve the issues mentioned above we introduced a cache update feature between the client and local cache using Redis pub-sub so that client should not go to Redis for the data in the ideal case.
Redis Pub/Sub
It is just a simple messaging platform where publishers send some messages and subscribers receive those messages. In this pattern, publishers can issue messages to any number of subscribers (API servers in our case) on a channel and subscribers subscribe to one or more channels. These messages are fire-and-forget, in that if a message is published and no subscribers exist, the message evaporates and cannot be recovered.
Implementation
Suppose some API has in-memory caching of X secs and we need to update its cache every X secs. What we did was we introduced a separate cron which will run every X — some jitter(<X secs) and will fetch new data from the database. Then it will update the Redis with new data and send the fresh data to the Redis pub-sub. Then All the API servers will receive the fresh data instantly through pub-sub and will update their local cache.
Problem 7
We were using two different Redis one for pub-sub and the other one for normal caching. After introducing the cache update feature we noticed huge spikes on pub-sub redis after the same regular intervals. It was happening due to our cron and increased Redis pub-sub usage. The spikes were not normal as we knew it will fail in future if more matches add to the matches list or more contests were to the contests list. Redis also has its limits because it is possible that a client sends more commands producing more output to the server at a faster rate than that which Redis can send the existing output to the client. This is especially true with Pub/Sub clients in case a client is not able to process new messages fast enough. Both conditions will cause the client output buffer to grow and consume more and more memory. For this reason by default, Redis sets limits to the output buffer size for different kinds of clients. When the limit is reached the client connection is closed and the event is logged in the Redis log file.
Pub/Sub clients have a default hard limit of 32 megabytes and a soft limit of 8 megabytes per 60 seconds.
Solution 7
Considering those spikes and Redis limits we dropped the idea of sending complete cache data to servers. Instead, we moved to the solution that we will only send the cache key to the servers. Servers will fetch fresh data from Redis and update their local cache. We compromised with this solution because it will fire X(no of API servers) no of requests in the ideal case at every regular interval which is still far better than cache stampede on Redis on peak time and it will solve the data consistency issue also.
Problem 8
We were not happy with the above solution because there was still a significant load on caching Redis. We deep dive into the caching data of our queries to investigate why it is taking a lot of time.
We use TypeORM (It is a simple ORM which maps tables to model classes. These model classes can be used to generate SQL migrations. Instances of the model classes then provide an interface for CRUD queries to an application at runtime.) for interacting with databases in our backend application.
We were using the inbuilt cache option of this ORM for our caching purpose. We noticed that TypeORM is taking around 2 MB of cache space for storing data of only one match and it is also taking a lot of time to fetch that data from Redis or in-memory cache.
After some research, we found the problem. Let me explain the problem with an example.
Suppose there are two tables TournamentTable and MatchTable.
TournamentTable

MatchTable

tournamentID is present in both tables and has one-to-many relation on this field. So when you join them and select all the files you get:
select * from TournamentTable a
join MatchTable b on a.tournamentID = b.tournamentID;Result
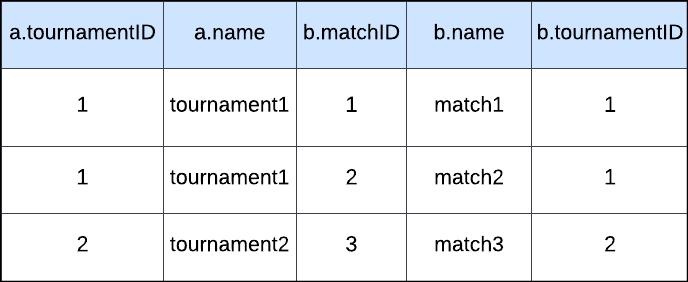
As you can see in the result, tournament data(a.tournamentID, a.name) is repeated for matchId(1 and 2). It is basically a raw data
So, what TypeORM does is it fetches raw data from queries and stores the same raw data in the cache. And before giving output it converts that raw data to model classes in which all the data is structured into objects according to their relations. The output example below:-
typeORMQueryResult = [
TournamentTable {
tournamentID: 1,
name: tournament1
_matches_: [
MatchTable{
matchID:1
name: match1
tournamentID:1
},
MatchTable{
matchID: 2
name: match2
tournamentID:1
}
]
},
TournamentTable {
tournamentID: 2,
name: tournament2,
_matches_: [
MatchTable{
matchID: 3
name: match3
tournamentID: 2
}
]
}
]As you can see data is structured according to their relations and data is not repeating here.
We have a lot of nested joins in our queries which have one-to-many relations which accumulate a lot of repeated data and hence huge raw data in the cache.
Also, It takes a significant amount of time to convert that huge raw data to structured js objects for every request.
Solution 8
To solve this issue, we introduced a custom cache layer for storing and fetching data from the cache. We are still fetching raw data from the database but we are not using the TypeORM inbuilt cache that stores raw data in the cache. We are now storing the final structured data objects in our Redis/in-memory cache.
Now it takes only 50–100KB space for one match, earlier it was 2MB. (95% improvement). Due to the significant reduction in Data Bandwidth in our multiple queries our lookup time from the cache also drastically reduced after this change. Later we moved some APIs to our previous approach(sending the whole data in Redis Pub/Sub instead of only the cache key) after this space optimisation.
Note — We were storing nested objects after converting them to strings as key-value pairs in Redis. When you fetch and parse that data it will give you a simple plain nested js object and not class objects but we needed model class objects for GraphQL output. So, we converted those plain objects to Class objects by TypeORM transformer. PlainObjectToNewEntityTransformer — TypeORM uses this transformer internally to convert those plain objects to class objects. You can find PlainObjectToNewEntityTransformer code in their GitHub repository.


