Introduction:
There’s a lot that goes behind the scenes in creating India’s largest social gaming platform serving millions of users and handling outrageous amounts of requests every minute. In this ever evolving industry, there’s hundreds of new exciting games, features and products that are integrated on a single platform — WinZO. If you have ever used any of these, you would have unknowingly came across a Silent Guardian, a Watchful Protector, A Hero that WinZO deserves and needs – The WinZO API Gateway 🦸♂️
The WinZO API Gateway Overview
The WinZO API Gateway at its core is a set of Nginx servers that act as a reverse proxy that accepts the requests from client (WinZO Application), gets the requests authenticated and then routes it to the required microservices.

Each server contains an Nginx configuration that contains settings and directives that control how Nginx should behave. The anatomy of a typical Nginx configuration file looks like this:
- Global Settings: basic settings such as worker processes, error log location, process id etc
- Events: specifies how Nginx should handle connection, timeouts and other events
- HTTP Server: server level settings such as Access log rotation, SSL certifications etc
- Location: defines how Nginx should handle requests to a particular URL or path, proxying it to another server or perform rewrites.
- Caching: defines how certain content should be cached to improve performance
The Challange🧩
So, its evident that this Nginx configuration file is sacrosanct. Managing the Nginx Configurations across multiple servers comes with its own set of challenges –
- Configuration drift: When multiple teams are working on new features, adding new APIs, they make changes to the Nginx configuration and over time this may lead to inconsistencies and potential security vulnerabilities.
- Scalability: As the numbers of Nginx servers grows, syncing the configurations manually/via scripts can become a daunting task which is also error prone.
- Testing: New changes may have unforeseen impact and may require quick rollback which in this case is not possible.
- No Transparency: Cannot see history of changes and understand impact of each change.
Having a single person or specific set of people doing these changes might solve some of these challenges but that is not scalable for a fast growing organization like ours. Now all eyes were on the DevOps team to find a safe, scalable, automated solution to all of these challenges, and to that we had only one reaction 😜:

The Goal 🥅
“If I had an hour to solve a problem, I’d spend 55 minutes thinking about the problem and 5 minutes thinking about solutions.” — Albert Einstein
Before arriving at a solution we need to understand what we are hoping to achieve and we arrived at these 5 simple goals:
- Simplify Deployment Process
- Enable self service for developers
- Promote transparency and observability
- Create history of deployment and using version control
- Increased deployment confidence and easier rollbacks
There’s plethora of tools & applications available in the market for configuration management and automations, but we also had to ensure the learning curve isn’t too steep for the developers, so that they could easily adopt it. Since our developers were already familiar with the AWS Console and Jenkins, we were inclined to build on the same platform.
The Solution💡
From here on things are about to get interesting 😁 The first step of building a completely automated solution was to move all the infra to code. We used terraform to create a custom module that brings up the load balancer, ASG instances, installs the required libraries, monitoring agents and of course, Nginx itself.
We moved the Nginx configuration to git and keeping in mind all the challenges we addressed before, we arrived at our solution: Blue/Green Deployment using AWS Code Deploy

What is Blue/Green Deployment ?
A blue/green deployment is a deployment strategy in which you create two separate, but identical environments. One environment (blue) is running the current application version and one environment (green) is running the new application version.
Using a blue/green deployment strategy increases application availability and reduces deployment risk by simplifying the rollback process if a deployment fails. Once testing has been completed on the green environment, live application traffic is directed to the green environment and the blue environment is deprecated.
Here’s What The Solution Architecture Diagram Looks Like:
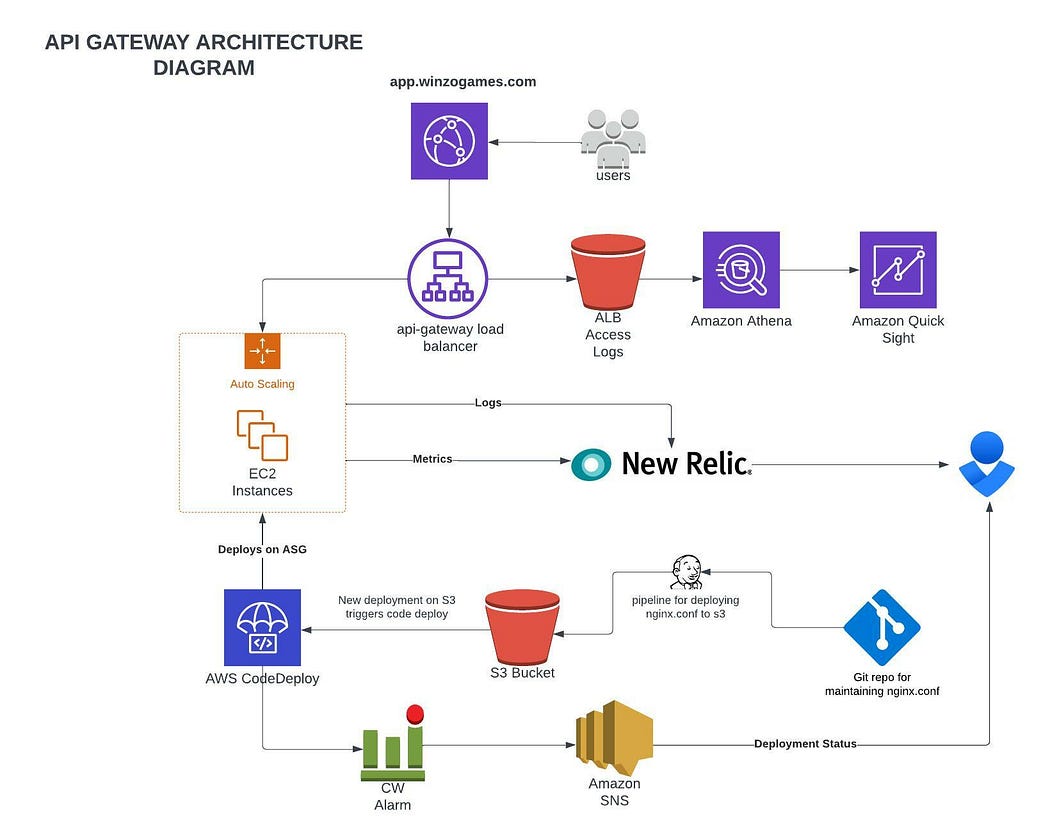
With AWS Codedeploy’s Blue/Green deployment for EC2 instances, you need to create a deployment group where you define the autoscaling group and target group for your deployments, define a deployment appspec.yml file which describes what, where and how to deploy. Connect your source code location and voila! You are all set to deploy.
Here’s an example of our appspec.yml file which simply describes where the nginx configuration file needs to be placed and how nginx should be reloaded.
version: 1.0
os: linux
files:
- source: /nginx.conf
destination: /etc/nginx/
- source: /reload.sh
destination: /root/
file_exists_behavior: OVERWRITE
hooks:
AfterInstall:
- location: reload.sh
timeout: 60
runas: rootWe created a Jenkins job using the Codedeploy plugin, which picks the code from git and pushes it to a versioned S3 bucket and triggers Codedeploy.
On triggering deployment, Codedeploy provisions a copy of the autoscaling group with the new deployment, once deployment is successful, it can be verified and we can proceed to replace the ‘Blue’ servers with the new ‘Green’ ones by clicking on ‘Reroute traffic’ in Codedeploy Console.
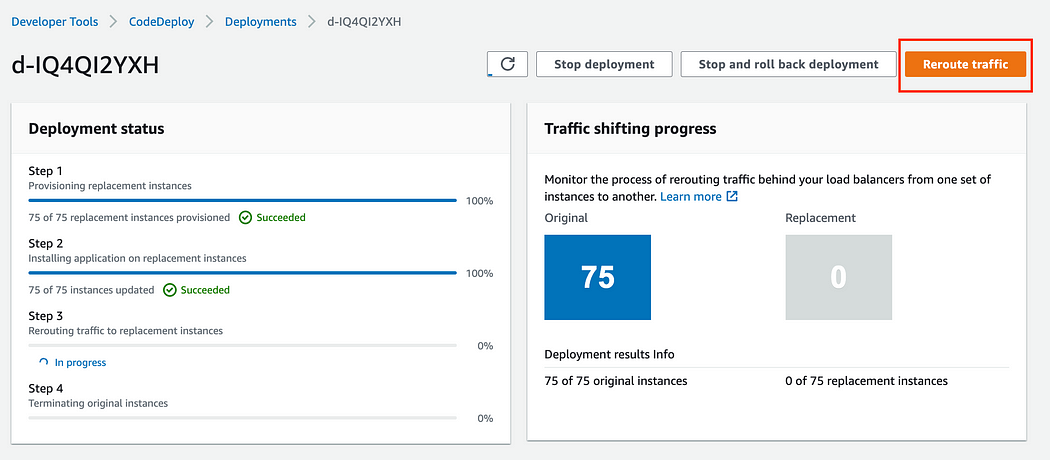
Although Blue/Green gives us the opportunity to test thoroughly before rerouting traffic to new deployment, it is still possible that some unforeseen issue comes up and the deployment needs to be reverted. In such a case we can simply click on ‘Stop and roll back deployment’ and our production environment can quickly jump back to the old servers that are already running with the stable build.
This significantly improves the MTTR (mean time to recovery) for an application.
In case the deployment is successful and there is no need to rollback the old servers, then they can be terminated manually, or they get terminated after a certain no. of hours which is defined in the deployment group configurations.
Testing The Green Fleet🧪
Before starting off with this project we noticed how Code Deploy creates the ‘Green’ fleet of instances by copying the ASG, but does not copy the load balancer, which would have allowed us to test the new fleet of instances with a single endpoint.
This ideally should have been part of the Code Deploy! (tsk tsk Notice me AWSenpai)
We solved this small caveat by having our own simple serverless automation solution using AWS Events and Lambda Function.
In our terraform module we added another permanent ‘testing’ load balancer and target group for the new green fleet. Whenever Code Deploy is triggered and new ASG is provisioned, a Lambda function gets triggered that attaches this ‘testing’ load balancer’s target group to the new ASG.
As soon as the deployment is successful on the new fleet of instance, we can use the “Test URL” i.e. the permanent AWS Route53 record that points to the testing load balancer for verifying the latest deployment before ‘Rerouting’ these new instances to the main load balancer using Code Deploy.
AWS Event Bridge Event :
{
"source": ["aws.codedeploy"],
"detail-type": ["CodeDeploy Deployment State-change Notification"],
"detail": {
"application": ["code-deploy-app"],
"deploymentGroup": ["code-deploy-deployment-group"],
"state": ["START"]
}
}Lambda Python Code:
import json
import boto3
import sys
import os
tg = boto3.client('elbv2')
cdep = boto3.client('codedeploy')
asg = boto3.client('autoscaling')
def lambda_handler(event, context):
## Getting the Deployment Details
eventresp = event['detail']
depid = eventresp['deploymentId']
print("Event Response:\n", eventresp)
dep_resp = cdep.get_deployment(deploymentId=depid)['deploymentInfo']
print("Deployment Info:\n", dep_resp)
# Target Group Name
tg_name = os.environ['TARGET_GROUP_NAME']
tg_arn = tg.describe_target_groups(Names=[tg_name])['TargetGroups'][0]['TargetGroupArn']
#List Existing Targets and remove if any
tgresp = tg.describe_target_health(TargetGroupArn=tg_arn)['TargetHealthDescriptions']
if len(tgresp) > 0:
old_targets = [x['Target'] for x in tg.describe_target_health(TargetGroupArn=tg_arn)['TargetHealthDescriptions']]
print("old_targets", old_targets)
dreg_resp = tg.deregister_targets(TargetGroupArn=tg_arn,Targets=old_targets)
# Get new ASG instances from deployment
deploy_asg = dep_resp['targetInstances']['autoScalingGroups'][0]
print("Deployment Autoscaling Group: ",deploy_asg)
asg_instances_resp = asg.describe_auto_scaling_groups(AutoScalingGroupNames=[deploy_asg])['AutoScalingGroups'][0]['Instances']
asg_instances = [id['InstanceId'] for id in asg_instances_resp]
print("ASG Instances to register", asg_instances)
new_targets = []
for instance_id in asg_instances:
inst_dict = {}
inst_dict['Id'] = instance_id
inst_dict['Port'] = 80
new_targets.append(inst_dict)
# Attach to Target Group
response = tg.register_targets(TargetGroupArn=tg_arn, Targets=new_targets)
print("New instances attached to test TG")
return {
'statusCode': 200,
'body': json.dumps('Targets Attached')
}Observability 🔬
If there’s on thing people in Tech dread the most, is the Murphy’s Law.
Anything that can go wrong will go wrong
But DevOps teaches us that, when it does, we need to have proper logging and monitoring to troubleshoot and fix the issue.
For this solution, we installed the New Relic Infrastructure agent for exporting all the regular metrics ( CPU, Memory, Disk Usage, Network Bandwidth etc) along with the Nginx Integration which provides additional metrics specific to the Nginx servers.
The load balancer access logs are forwarded to S3, which are then queried via Athena and dashboards can be created using Quicksight/Grafana to readily provide essential insights on the incoming traffic. Appropriate metrics are monitored and alarms are applied to inform the team whenever anything out of ordinary is reported.
Rollout 🤘
The Rollout was seamless, and the solution began yielding results in a very short span of time. The entire daunting manual deployment process was out of the window and developers started doing more deployments without fear.
Issues started getting noticed before the changes went live and were resolved. Revisiting and improving old architecture also resulted in some enhancements in performance and cost optimisations by using the latest generation of instance and volumes. All in all, life was much simpler now 🥹

In a Blue world, the grass may be Greener on the other side!
This was the first blog in the DevOps series of our tech blogs. The DevOps Team @ WinZO is always on the lookout for innovations and automations. There are a lot more exciting projects that we are working on, and we just can’t wait to share those stories here, so stay tuned for more!
As India’s Largest Interactive Entertainment Company, Winzo envisions establishing India as the next Gaming Superpower of the world, fuelled by revolutionary innovations and path-breaking engineering. Resonate with our vision? Visit our Careers page (https://winzogames.hire.trakstar.com/.) and reserve a seat on our Rocketship


