Introduction
The rapid growth in Fantasy sports players and the increasing complexity of our systems have brought their own set of challenges for the tech team at WinZO. Discussing those is what we are here for but first, let’s take a deeper dive into the world of ‘fantasy’. 🚀
What is fantasy?
Fantasy is a game where you choose players from real matches to make your teams and then compete with other people. The team points are then calculated according to the real performance of your chosen players in that particular match. Overall, it involves numerous matches with various contests in a single match, the sum of which makes its way to a leaderboard.
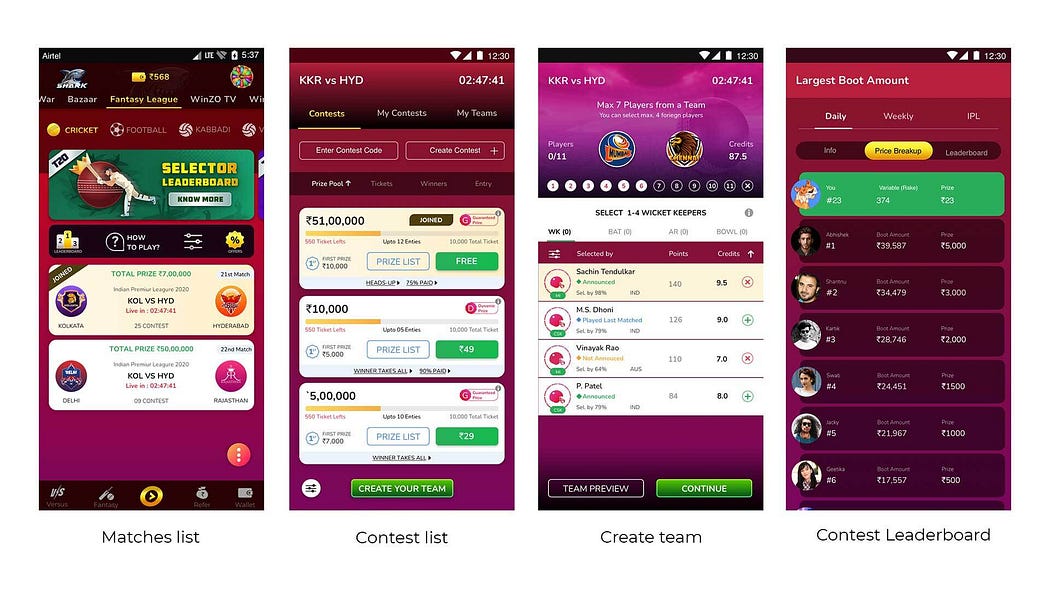
Traffic Patterns
Unlike other games on WinZO, the traffic pertaining to Fantasy is not linear and is rather very seasonal. For example, during IPL the ‘fantasy’ tab attracts a lot of users and we see a huge surge of throughput on our servers. Even during the course of a particular season, high throughput is dependent upon certain events in a match. For example, after the announcement of the actual squads, a lot of users rush to the system to edit their original teams or make new teams. While many users also come to check their position on leaderboards whenever a celebrated player, who is likely to be on the teams of most users, starts to score more runs. All these events have a direct correlation with the traffic on our systems. Within a couple of minutes, our max throughput becomes 5X and that’s why services like AWS auto-scaling do not work for us. By the time auto-scaling kicks in, our users have already come and gone. So we had to build a system that can handle whenever there is a sudden surge in traffic.
How did we start to build?
To begin with, let’s talk about how caching helped us overcome all the challenges that we faced as we started to grow. Let’s go back to the last 2 to 3 years and discuss how we progressed and scaled the Fantasy feature to handle high volumes of traffic. Before IPL 2020, we designed Fantasy with a simple cache structure and hoped that it will work well.
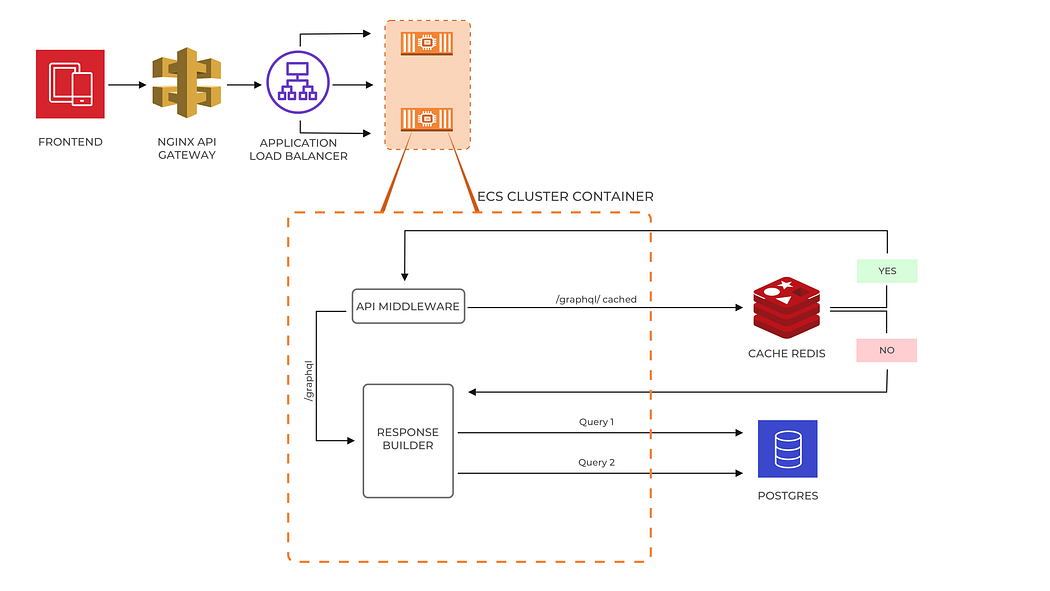
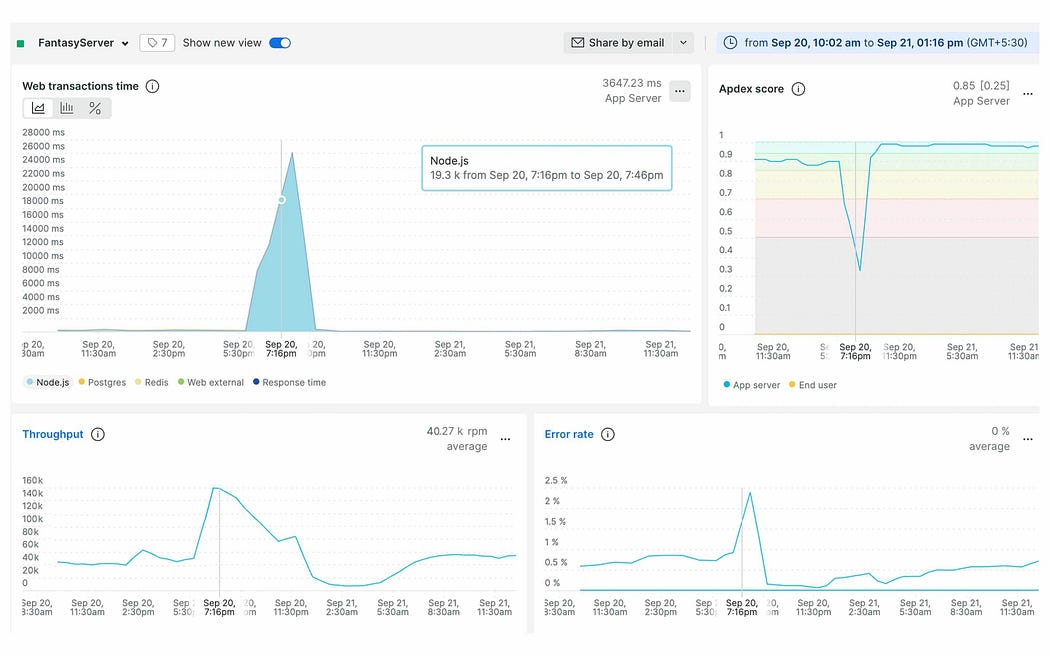
30 minutes before the start of the first match of IPL 2020, we saw a sudden surge in traffic on the new relic. Within a couple of minutes, our throughput increased to 4X and usage of specific APIs like (“update teams”) increased to 40X — 60X. As a result, our fantasy home page wasn’t responding and APIs were giving a timeout.
We opened AWS RDS matrices and noticed that queries were taking 6–7 mins to run; meanwhile, DB CPU reached 100% and DB Session counts were touching their all-time high and API response time reached 26K ms. All this resulted in a downtime of 20–30 mins. We observed that a lot of queries which shouldn’t be running due to the Redis cache layer were also running on the DB. Later on, we concluded our system was facing a ‘cache stampede’ issue.
Problem 1 — Cache Stampede on Database.
‘Cache stampede’ is a type of failure in the caching system that occurs when a lot of parallel systems try to access data from the cache layer at the same time. In such a case, if the key is already expired, no one finds it and everyone goes to the base layer. That was the reason for our high DB queries, when the Redis cache expired, all queries went to the DB.
Solution 1 — Query level caching in APIs.
To solve this issue, we started focusing on parts of the system with the highest throughput as not all parts will going to be hit by the same scale. For example, the ticket purchase throughput would be much lower compared to the home page API throughput. We had two main observations:
1.) All those who are coming to the WinZO Fantasy tab, load the first page and then click on the ‘match’ card for match info and contest list. This happens irrespective of a user’s motive for coming to that tab, whether to play or buy a ticket. So, we filtered out 3 APIs with the highest throughput that is the match list, match info, and contests list.
2.) These APIs responses are constructed by many small queries and everyone is going to the database and coming up with the same data.
We filtered out-static queries(whose data does not change regularly) and dynamic queries. We cached all these queries separately on Redis with different cache expiry times according to the type of data they serve. After that, our Redis usage heavily increased but we were able to temporarily solve the issue for a scale even 6X surge in traffic . But we knew this solution will also fail for higher throughput.
Alas! After a few days, we again had an outage before the match. This time database metrics were looking good and Db CPU percentage and session counts were normal. The moment we opened Redis metrics, we were stunned and yes you guessed it right, they were bleeding.
Problem 2 — Redis Limits Breaches
Redis engine CPU utilisation reached 100%, get type commands reached its peak on redis which each node can handle and response time increased to 5000 ms. To solve this, we had to blindly add replica nodes in every Redis cluster where we could and hoped for the best and it worked. But there is a limit on the no of read-replica nodes you can add to the Redis cluster.
Each shard in a replication group has a single read/write primary node and up to 5 read-only replica nodes, which is the maximum number of replicas allowed.
We later moved on to the long term solution for this and then we came up with in-memory caching on API servers.
Solution 2 — InMemory Caching on API Servers
Memory Caching is a technique in which a system temporarily stores data in its main memory (i.e., random access memory, or RAM) to enable fast retrievals of that data. It is the fastest caching method, since accessing RAM is significantly faster than accessing other media like hard disk drives or from other networks(eg- Redis, database, etc).
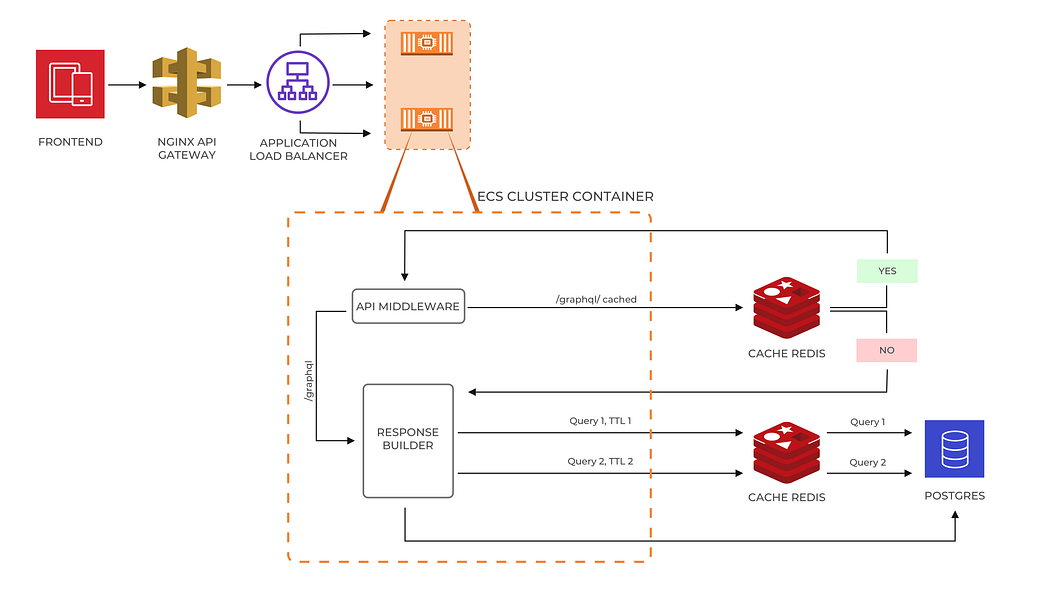
So, We added one more layer of in-memory caching to the current caching architecture.
The new cache architecture looks like this.
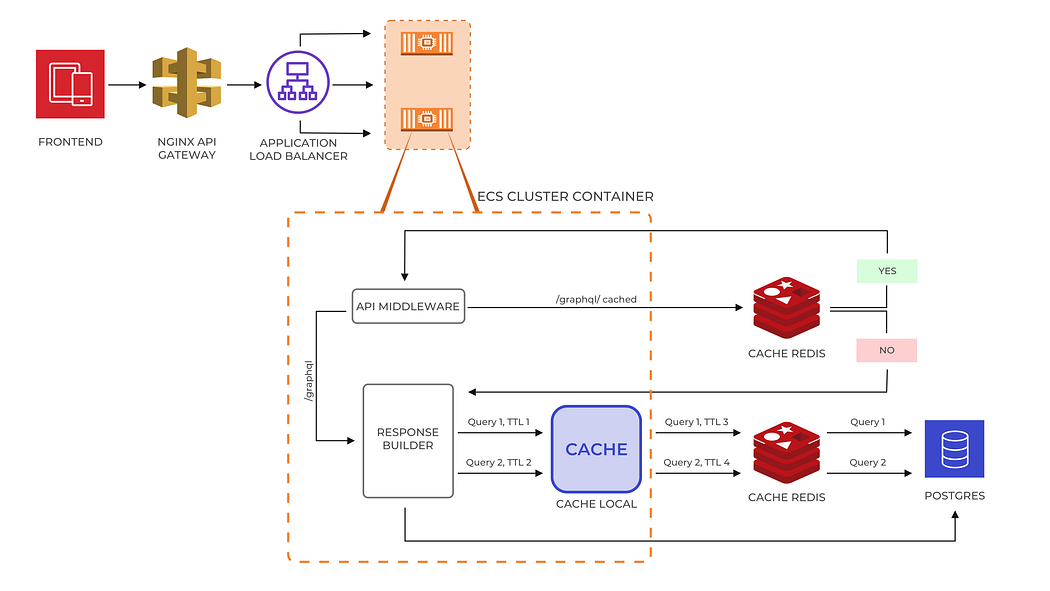
This was the game-changer for us. Our response time was reduced to 13 ms with a throughput of 6X. Our Redis usage was also reduced. We thought it will work even for 10X of the current throughput and IPL 2020 ended with this happy ending.
IPL 2021
Welcome to IPL 2021.
Max Traffic on fantasy is increased to 3X of earlier season. While our solution worked for starting matches but after some days, we again faced downtime of 10–15 mins. The reason was Redis get-type commands suddenly spiked and got back to normal after some time. After going through different metrics we concluded that it is due to a cache stampede on Redis.
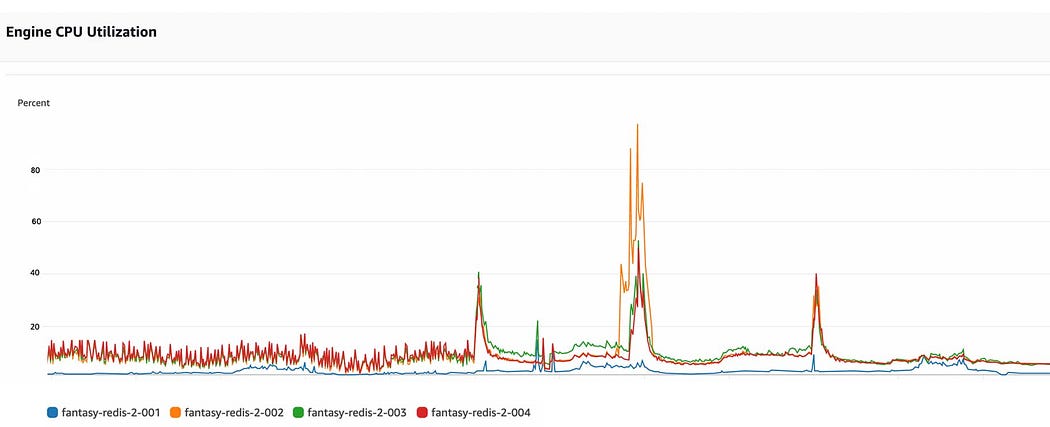
Problem 3 — Cache stampede on Redis
We were again facing the issue of cache stampede but this time on Redis. The local memory Cache on all the API servers was expiring at almost the same time and every request was going to Redis.
Solution 3 — Added Jitter on API Servers.
To solve the cache stampede on Redis we added slight jitter in our cache expiry time. Jitter is a randomly generated time [for example — TTL = Actual TTL in Seconds + some jitter(random between 0 -10% of Actual TTL)]. It is used to reduce pressure on your servers. By adding jitter in our TTLs, we reduced the load on Redis and that year fantasy performed well.
Months before growling IPL 2022
We had 2–3 months left for IPL 2022 and the business team was expecting 3–4X of throughput in the upcoming IPL. We had to make our system tolerable for that. By now we had developed our load testing platform which you can read here:
https://tech.winzogames.com/performance-testing-simulating-random-spikes-in-traffic-with-low-cost-testing-infrastructure-462b727817b8. We made a plan to load test all the fantasy APIs with 10X of the current throughput. While load testing we observed something peculiar.
Problem 4- Time-consuming creation of GraphQL Objects.
We observed that some static APIs whose response time should ideally be less than 50 ms is taking around 150 ms at a 10X scale. In these Apis, we construct a large Js graphQL object from many small queries which are already cached in the memory. For every API request, this object parsing and creation happens. So, we made a hypothesis that this JS object creation is the culprit which is taking a lot of time because everything else is Cached in the memory.
Solution 4 — Cached final response
We cached the final JS object which is formed after all the computations, in the memory. Our hypothesis worked and the static APIs response time was reduced to 4ms from 150ms (97% improvement).
Problems Left After Load Testing
1.) Data inconsistency: Due to jitter in cache TTL on API servers we were facing a data inconsistency issue. In simple words, sometimes users saw new data on the app and sometimes old.
2.) Delay in squad info: When squads for a match are announced, we need to reflect that information immediately on the app. So that users know which players will be playing. With this information, they can then make new teams or edit existing teams. But due to the local memory cache on API servers, that information was reaching the end-users after some delay.
3.) Fear of failing this solution for even higher throughput: Even after the jitter solution, we knew that for higher throughput there will be a significantly higher load and cached stampede on Redis.
To solve all these issues we made a cache update feature which will be discussed in the next part of our series Fantasy: The Great Cache Game.
As India’s Largest Interactive Entertainment company, WinZO envisions establishing India as the next Gaming Superpower of the world, fuelled by revolutionary innovations and path-breaking engineering. Resonate with our vision? Visit our Careers page ( https://winzogames.hire.trakstar.com/) and reserve a seat on our Rocketship.


